import pandas as pd
url = "https://gitlab.com/labsysmed/dissecting-bias/-/raw/master/data/data_new.csv?inline=false"
df = pd.read_csv(url)Replication Study: Dissecting racial bias in an algorithm used to manage the health of populations
2024-03-08
The expectations for all blog posts apply!
This blog post is a replication study. In this post, you will read a famous scholarly paper on racial bias in a healthcare recommender system; replicate its primary findings; and discuss your results.
Preparation
To prepare to complete this blog post, you need to do three things:
First, read this journal article
Obermeyer, Ziad, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. “Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations.” Science 366 (6464): 447–53.
Second, watch the concise high-level discussion of this paper in the video “Are We Automating Racism?”.
I recommend the entire video, but the discussion of this paper runs from approximately 14:45 to 17:51. The discussion features Dr. Ruha Benjamin, a prominent critical scholar of technology and society. She is the author of the well-known book Race After Technology, as well as several others.
Third, reread the article in the context of Dr. Benjamin’s discussion.
Now, proceed on to the next parts.
Part A: Data Access
In order to protect patient privacy, the authors did not share the “real” data used in their study. Instead, they created a randomized version of the data that preserves many of the same patterns and trends. You can use the code below to access the data.
Poke around the data a bit. You should consult the code repository provided by the authors, especially the data dictionary, in order to interpret the meaning of the rows and columns.
A few of the columns are especially important:
risk_score_tis the algorithm’s risk score assigned to a given patient.cost_tis the patient’s medical costs in the study period.raceis the patient’s self-reported race. The authors filtered the data to include onlywhiteandblackpatients.gagne_sum_tis the total number of chronic illnesses presented by the patient during the study period.
Part B: Reproduce Fig. 1
Please make a plot in which you reproduce Fig. 1A of Obermeyer et al. (2019). Your figure is not required to be exactly the same, but it must visualize risk score percentiles against mean number of active chronic conditions within that percentile. For example, I thought I would try spliting out male and female patients. I also think the figure looks a bit nicer with axes inverted. So, my result looked like this:
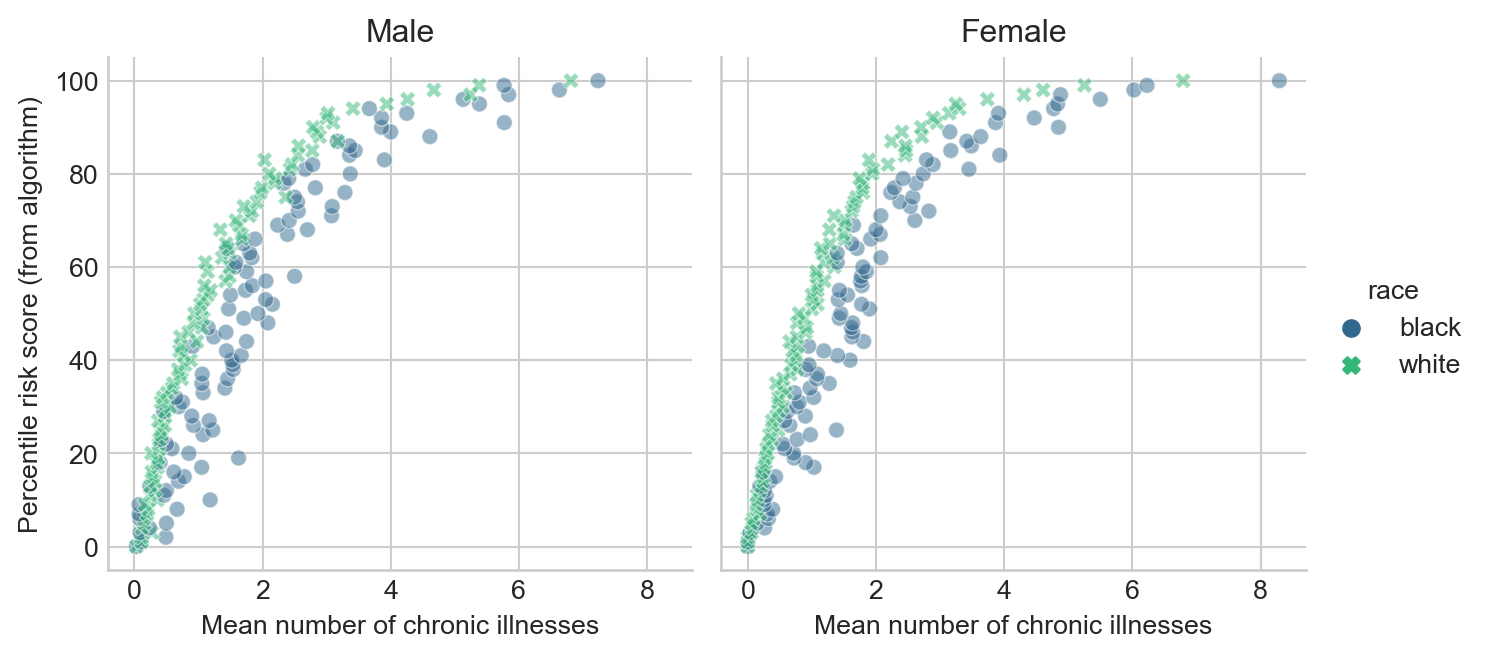
Please make sure to appropriately label all axes, legends, and plot facets.
Include a brief discussion of the meaning of this plot. Suppose that Patient A is Black, that Patient B is White, and that both Patient A and Patient B have exactly the same chronic illnesses. Are Patient A and Patient B equally likely to be referred to the high-risk care management program?
Part C: Reproduce Fig. 3
The authors write that
…there are many opportunities for a wedge to creep in between needing health care and receiving health care—and crucially, we find that wedge to be correlated with race…
To support their argument, they produce Figure 3. This figure shows how total medical expenditures are correlated with the risk score and with the number of chronic health conditions. Please produce a version of Figure 3, including both panels. For the horizontal axis in the second panel, please use the number of chronic conditions. It is not necessary to draw threshold values in the same way as the authors. Here’s an example output.
Notes:
- In my version of the first panel of Figure 3, I plot the mean expenditure within each risk score percentile.
- Although not explicitly labeled, I believe that the righthand panel of Fig. 3 in Obermeyer et al. (2019) has percentiles in the number of chronic conditions on the horizontal axis. I’m uncertain how they computed these, considering that in our sample data set the maximum number of chronic conditions is 17. This implies that either the original data set has patients with more chronic conditions or the authors did something to arbitrarily break ties. To avoid dealing with this, please simply use the number of chronic illnesses for your horizontal axis. Here’s an example of my solution:
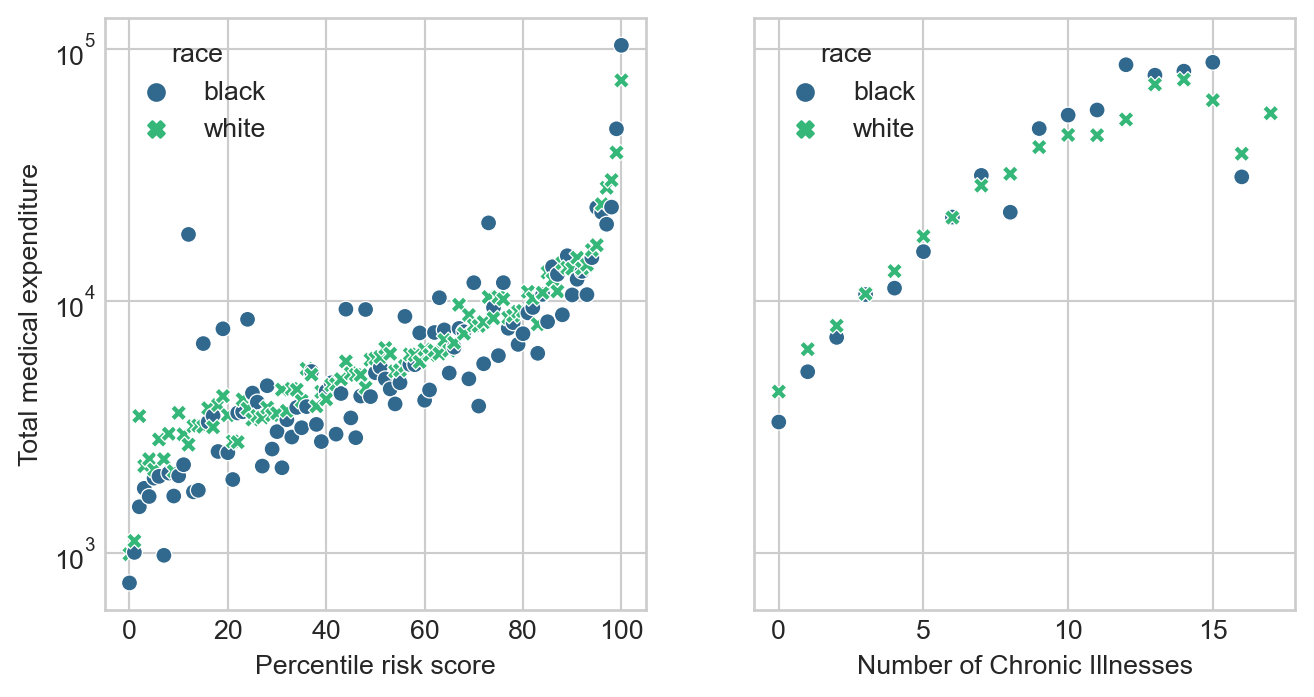
plt.subplots to create a figure with two panels, and then sns.scatterplot to populate each of the panels.Comment on your findings. You may find it useful to note that the vast majority of patients in this data set have 5 or fewer chronic conditions, as you will confirm in Part D.
Part D: Modeling Cost Disparity
You’ll notice that there is a relatively stable pattern of disparity in the cost incurred by Black and white patients with 5 or fewer chronic conditions, but that this pattern begins to swing wildly in one direction or another as the number of active chronic conditions increases. This is likely a reflection of the smaller number of data points as the number of conditions increases, which exacerbates the wild variability of healthcare costs.
Let’s see if we can quantify the disparity that we observe in patients that have 5 or fewer active chronic conditions.
Data Prep
- First, determine the percentage of the patients in the data with 5 or fewer chronic conditions. Does this percentage justify the choice to focus on these patients?
- Create a new column of the data set which is just the logarithm of the cost. This is called a log-transform. We’ll use this as our target variable. Log transforms are common when the target variable varies widely across several orders of magnitude. Because \(\log(0)\) is undefined, you should subset the data so that patients who incurred $0 in medical costs are removed.
- Create a dummy (one-hot encoded) column for the qualitative race variable in which
0means that the patient is white and1means that the patient is Black. - Separate the data into predictor variables
Xand target variabley(the log-cost). For predictor variables, just use the dummy columns for race and the number of active chronic conditions.
Modeling
Your figure from the previous part suggests that the relationship between the number of chronic conditions and the cost might be nonlinear. For this reason, we are going to fit a linear regression model with polynomial features in the number of active chronic conditions in order to to account for the nonlinearity. Here’s a mathematical description of our model:
This is a relatively “casual” approach to modeling and should be viewed as exploratory rather than statistically confirmatory.
\[ \begin{aligned} \log \mathrm{cost} \approx w_b \times (\text{patient is Black}) + \mathrm{intercept} + \sum_{i = 1}^k w_k\times (\text{gagne sum})^k\;. \end{aligned} \]
Our primary statistical interest is in the value of the coefficient \(w_b\). In the context of a log-transformed linear model, \(w_b\) has the following interpretation: the number \(e^{w_b}\) is an estimate of the percentage of cost incurred by a Black patient in comparison to an equally sick white patient.
To estimate \(w_b\), we can use a linear regression model, which is supplied by scikit-learn. How many polynomial features should we use? A simple way to figure this out is cross-validation. Here’s a function that will construct data sets with polynomial features of various sizes:
def add_polynomial_features(X, degree):
X_ = X.copy()
for j in range(1, degree):
X_[f"poly_{j}"] = X_["gagne_sum_t"]**j
return X_Use this function to loop through polynomial features of varying degrees. For each possible degree, construct a LinearRegression model and compute its score on the expanded data using cross-validation. From your results, determine a reasonable value of the polynomial degree that appears to led to the best predictions on this data set. There may be several reasonable choices.
Once you have determined a degree that seems reasonable for this data set, construct a copy of the data with the correct number of polynomial features and fit one last linear regression model.
You can access the coefficients of the linear regression model as LR.coef_. Determine which of these coefficients corresponds to Black race (the coefficients are in the same order as the variables in the data frame used for training). Finally, compute \(e^{w_\mathrm{b}}\). What is your estimate of the cost incurred by Black patients as a percentage of white patients. Does it roughly support the argument of Obermeyer et al. (2019)?
Part E: Abstract and Discussion
Please add an introductory “abstract” section to your blog post describing the high-level aims of of your analysis and an overview of your findings. The abstract should be no more than one paragraph. Then, add a closing “discussion” section of your blog post in which you summarize your findings and describe what you learned from the process of completing this post. In your discussion, please address the following question:
Of the formal statistical discrimination criteria discussed in Chapter 3 of Barocas, Hardt, and Narayanan (2023), which of these criteria best describe the purported bias of the algorithm studied by Obermeyer et al. (2019)? What aspects of the study support your answer?
© Phil Chodrow, 2024
References
Barocas, Solon, Moritz Hardt, and Arvind Narayanan. 2023. Fairness and Machine Learning: Limitations and Opportunities. Cambridge, Massachusetts: The MIT Press.
Obermeyer, Ziad, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. “Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations.” Science 366 (6464): 447–53. https://doi.org/10.1126/science.aax2342.